
Seedance 2.0 是 2026 年关注度最高的 AI 视频模型之一。这篇 Seedance 2.0 深度解析聚焦创作者真正需要的信息:可验证的能力、定价背景、接入路径和实用落地方式。

目前最公开且可验证的信息是 15 秒多镜头输出和多模态参考流程。官方发布措辞里最关键的一点是:Seedance 2.0 被描述为统一的多模态音视频联合生成模型,而不是先生成视频再后加音频的流水线。
为什么这个架构选择在实际创作流程里很重要?下面展开。
Seedance 2.0 与音视频同步问题
AI 视频生成里的常见挑战是:很多流水线会在视觉生成之后再处理声音。典型流程是:
- 根据提示词生成视频帧
- 分析这些帧中发生了什么
- 再补充“匹配”的音频
- 然后祈祷口型同步不要像糟糕配音片
人类会同时处理视觉和音频信息。一旦不同步,感知质量会迅速下降。
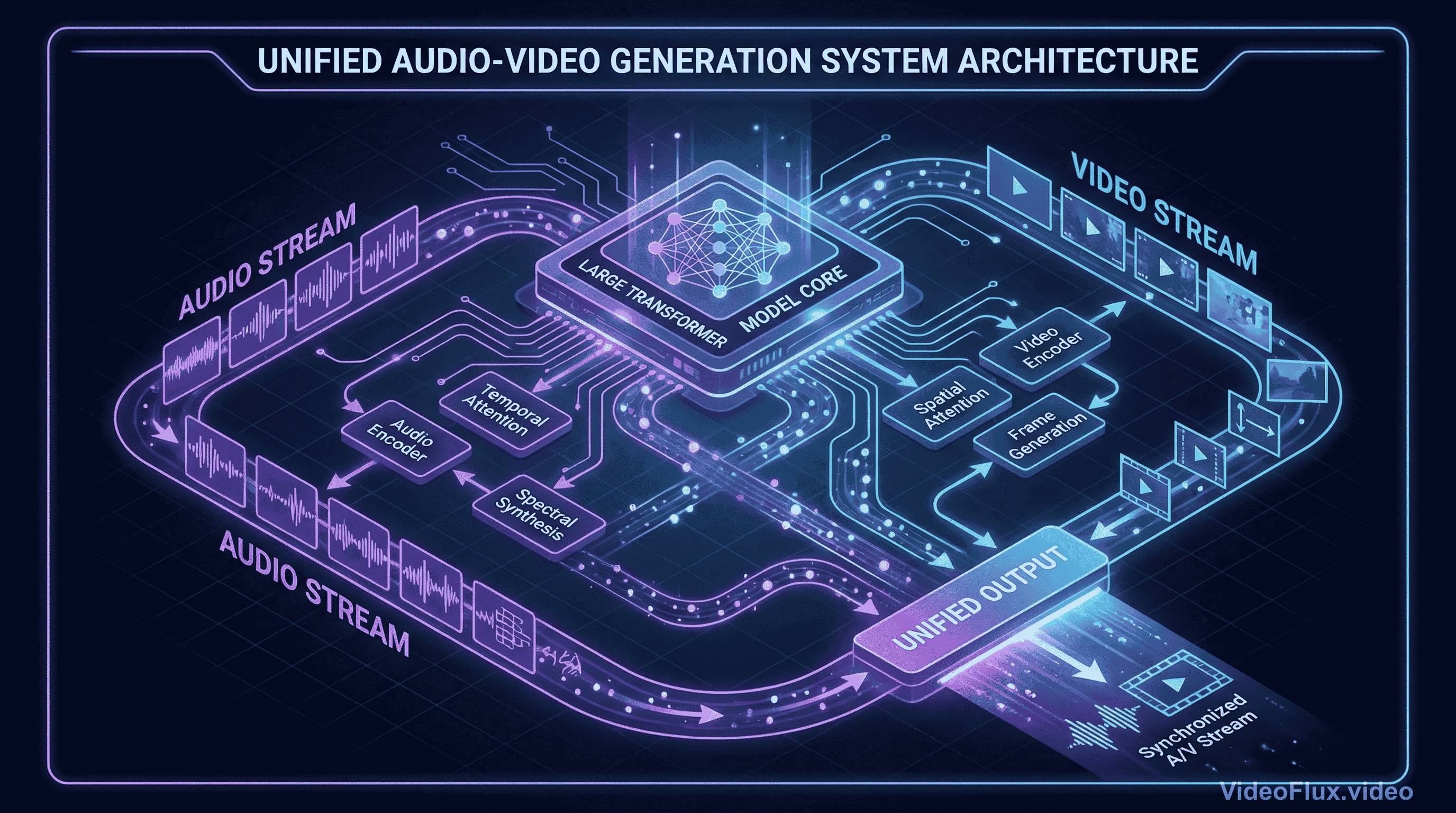 图 1:音视频联合生成的概念示意
图 1:音视频联合生成的概念示意
Seedance 2.0 在字节 Seed 的官方描述中,是统一的多模态音视频联合生成系统,支持文本、图片、音频、视频输入。官方发布还提到混合参考输入上限是 9 张图片、3 段视频、3 段音频。
从实操角度看,联合音视频生成相对严格串行流水线,理论上应能减少音画漂移;但具体质量差距仍取决于提示词设计和平台实现。
Seedance 2.0 的 @ 参考流程
再看大家容易一带而过的 @ 参考系统。表面看它像语法糖,是在提示词里标注元素的方式:
@character(girl.jpg) walks through @setting(cyberpunk_street.png)
while @music(synthwave.mp3) plays in the background从可追溯来源能得出的重点是:参考驱动提示是 Seedance 2.0 流程的核心。
 图 2:参考提示示例
图 2:参考提示示例
传统文生视频常常像隔墙喊话:“更有电影感一点!”更有电影感到底是哪种?更多镜头光晕?更慢运动?更低饱和度?模型会在多层抽象里猜你的意图,常常猜错。
@ 风格流程为参考对象提供了直接控制点。你不再只靠描述文本,而是能用明确资产锚定角色、场景和音频意图。
例如,Seedance 2.0 公开材料提到可混合输入最多 9 张图 + 3 段视频 + 3 段音频。这个输入预算对于品牌和角色一致性流程很有价值。
在专业场景里,这通常能降低提示词解释歧义。结果仍会随场景复杂度变化,但参考输入整体上会提升可重复性。
Seedance 2.0 多镜头生成流程
15 秒时长是当前公开文档中的真实产品约束。
字节发布说明强调多镜头输出和可控延展/编辑。实践中,最有效方式通常是把提示词写成明确镜头序列,而不是单场景描述。
举个具体场景。提示词:“一位厨师做菜、尝一口,然后微笑看向镜头。”看起来很简单。
更实用的写法是拆成三个明确节拍:
- 远景:厨师在操作台工作(建立情境)
- 近景:品尝时若有所思(情绪点)
- 中景:转向镜头微笑(结果点)
转场平滑度、连续性和节奏质量都应在固定提示词下逐案验证。
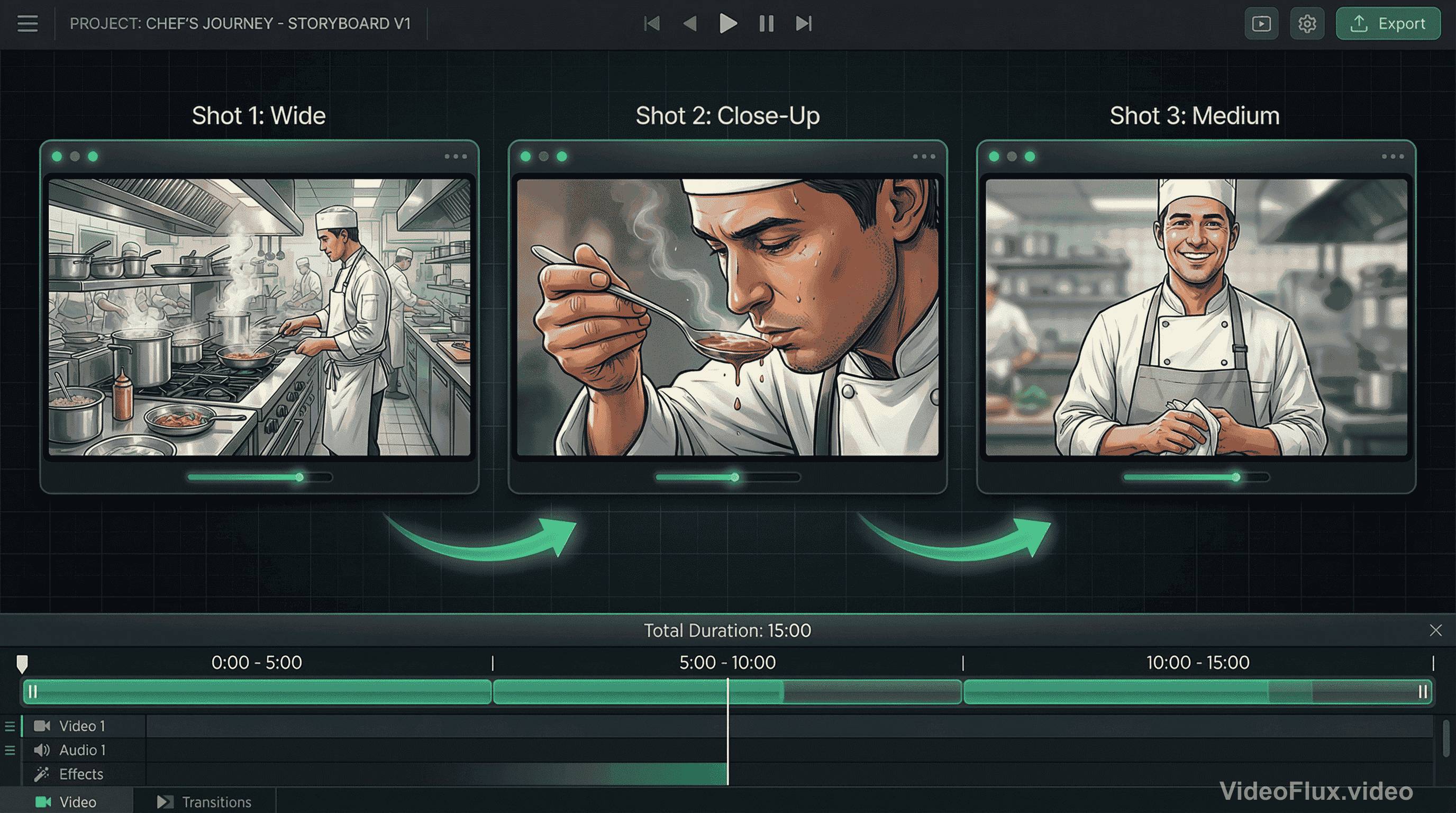 图 3:多镜头序列示例
图 3:多镜头序列示例
对创作者来说,当单次输出已包含连贯镜头变化时,可减少手工拼接工作量。
Seedance 2.0 的物理表现与长时一致性
公开的一手资料并未提供一个中立的跨厂商基准,足以对 Seedance 2.0、Sora 2、Veo、Kling 的物理质量做结论性排序。
Sora 2 在 OpenAI 官方描述中强调较前代更好的物理准确性和音频同步。字节同样声称 Seedance 2.0 相比 1.5 在物理与运动方面有显著提升。在缺少统一独立基准协议的前提下,这类说法应视为厂商自报。
15 秒上限在公开文档里也是真实约束。更长序列通常需要拼接或延展流程,并应专门测试连续性。
可用性方面,官方发布更清晰:Seedance 2.0 上线于即梦、豆包和火山引擎方舟体验通道。另有 fal.ai 公布其平台上的 Seedance 2.0 可用性与 API 接入。
如果你围绕特定模型搭建生产流程,这一点非常关键。把核心项目押在 Seedance 2.0 上,意味着要接受可能与自身需求不匹配的地域和平台约束。
Seedance 2.0 对比框架(客观测试)
与其做固定排名,不如在不同模型上使用同一套提示词和同一套评分标准。
 图 4:对比占位图(示意图,非基准输出)
图 4:对比占位图(示意图,非基准输出)
面向营销内容(15 秒社媒短片): 通过重复运行,衡量指令遵循、品牌一致性和音画同步质量。
面向电影感辅助镜头(B-Roll): 在相同镜头语言提示下,比较运动真实度、伪影率和时间一致性。
截至 2026 年 3 月 8 日,Google Vertex AI 公示了 Veo 的多档定价,包括 Veo 3.1 720p/1080p 视频生成为 $0.20/秒,720p/1080p 音视频生成为 $0.40/秒,并提供独立 4K 价格。
面向角色叙事: 测试口型同步准确度、对白清晰度和跨镜头身份一致性。
面向规模化成本效率: 基于官方最新定价页追踪实际账单,并按月重算,因为费率和打包策略可能变化。
Seedance 2.0 对 2026 年视频创作者意味着什么
战略问题不是“哪个模型最好”,而是“哪个模型最适合我的具体流程和内容类型”。
把流程绑定在单一模型上的创作者,常常会在模型短板碰上项目需求时遭遇瓶颈。更聪明的方式是具备多模型灵活切换能力。
例如,常见多模型流程可能是:
 图 5:多模型流程概念图
图 5:多模型流程概念图
- 概念测试:Kling 3.0(快、便宜、适合迭代)
- 角色开发:Seedance 2.0(一致性、口型同步)
- 主镜头:Veo 3.1(关键帧最高质量)
- 重物理场景:Sora 2(液体、布料、复杂交互)
每个模型都有不同约束和强项。最稳妥的方式是按任务做证据驱动的模型选择。
2026 年更大的趋势是:我们正从“提示词工程”走向“参考编排”。 文本提示依然重要,但未来属于那些允许你从多模态组合场景的模型。上传产品图、品牌风格指南、旁白音轨、运动参考视频,再由模型合成为连贯输出。
Seedance 2.0 清晰体现了这一转向,尤其适用于短时长、重参考的创作场景。
Seedance 2.0 实用建议
如果你正在试用 Seedance 2.0,基于其架构可以参考以下实务建议:
1. 把参考素材前置。 不要把 @ 系统当可选元数据,它是你的主要控制面。花时间整理真正符合目标的参考图片。
2. 以多镜头思维来写提示词。 与其写“一个人走路”,不如写“远景:一个人进入房间;近景:露出惊讶表情;过肩镜头:看到他正在看的对象”。给模型明确镜头结构。
3. 音频参考常被低估。 很多人会因为没有完美音轨而跳过音频输入。用节奏和情绪合适的占位音频也行,模型适配能力往往比预期更好。
4. 15 秒限制不是缺陷,而是特性。 顺着它工作。微叙事会迫使你聚焦关键叙事节拍。极简场景往往比把太多内容塞进一个片段得到更好结果。
5. 有策略地拼接。 如果你需要更长序列,优先设计自然过渡点。角色转身、镜头摇移、光线变化,这些都比生硬切点更能隐藏拼接痕迹。
Seedance 2.0 结论
Seedance 2.0 不是所有视频流程的全面替代方案。最稳妥的定位是:它在短时长、多模态参考、音视频同步生成任务上是强选项。
音视频联合生成路线已经明确出现在多个领先模型路线图中,Seedance 2.0 是字节在这一方向上的一个重要公开实现。
如果你的工作负载依赖短时长且重参考输出,Seedance 2.0 值得直接测试。如果你的工作负载依赖长时连续性,建议先做并排试验再决定。
参考驱动控制与原生音频生成,正在成为现代 AI 视频流程的核心能力。
我们仍处于这条技术曲线早期。实际问题不是对单一模型忠诚,而是如何把每个模型用在它可测量最强的位置。
这正是 VideoFlux 正在构建的方向:为生产流程提供多模型接入与编排工具。
想试用 Seedance 2.0 和其他视频生成模型?VideoFlux 提供统一入口,可在同一平台接入 Sora、Veo、Kling 和 Seedance。
延伸阅读
- ByteDance Seed: Official Launch of Seedance 2.0
- ByteDance Seed: Seedance 2.0 Product Page
- What Is Seedance 2.0? A Guide With Examples | DataCamp
- Google Vertex AI Generative AI Pricing
- OpenAI: Sora 2 Is Here
- OpenAI: Sora 2 System Card
- fal.ai: Seedance 2.0
Seedance 2.0 常见问题
什么是 Seedance 2.0?
Seedance 2.0 是字节 Seed 在 2026 年推出的视频生成模型。根据官方产品资料,它支持多模态输入(文本、图片、音频、视频)。
Seedance 2.0 适合做短视频吗?
公开发布文档中,Seedance 2.0 的定位包含 15 秒多镜头短时生成能力。
Seedance 2.0 支持参考驱动提示吗?
Seedance 2.0 的发布页和产品页都强调了多模态参考,包括图像/视频/音频混合输入。
团队应该如何评估 Seedance 2.0 与其他模型?
使用固定提示词、重复运行和可量化评分(同步质量、一致性、指令遵循、伪影率和成本)。